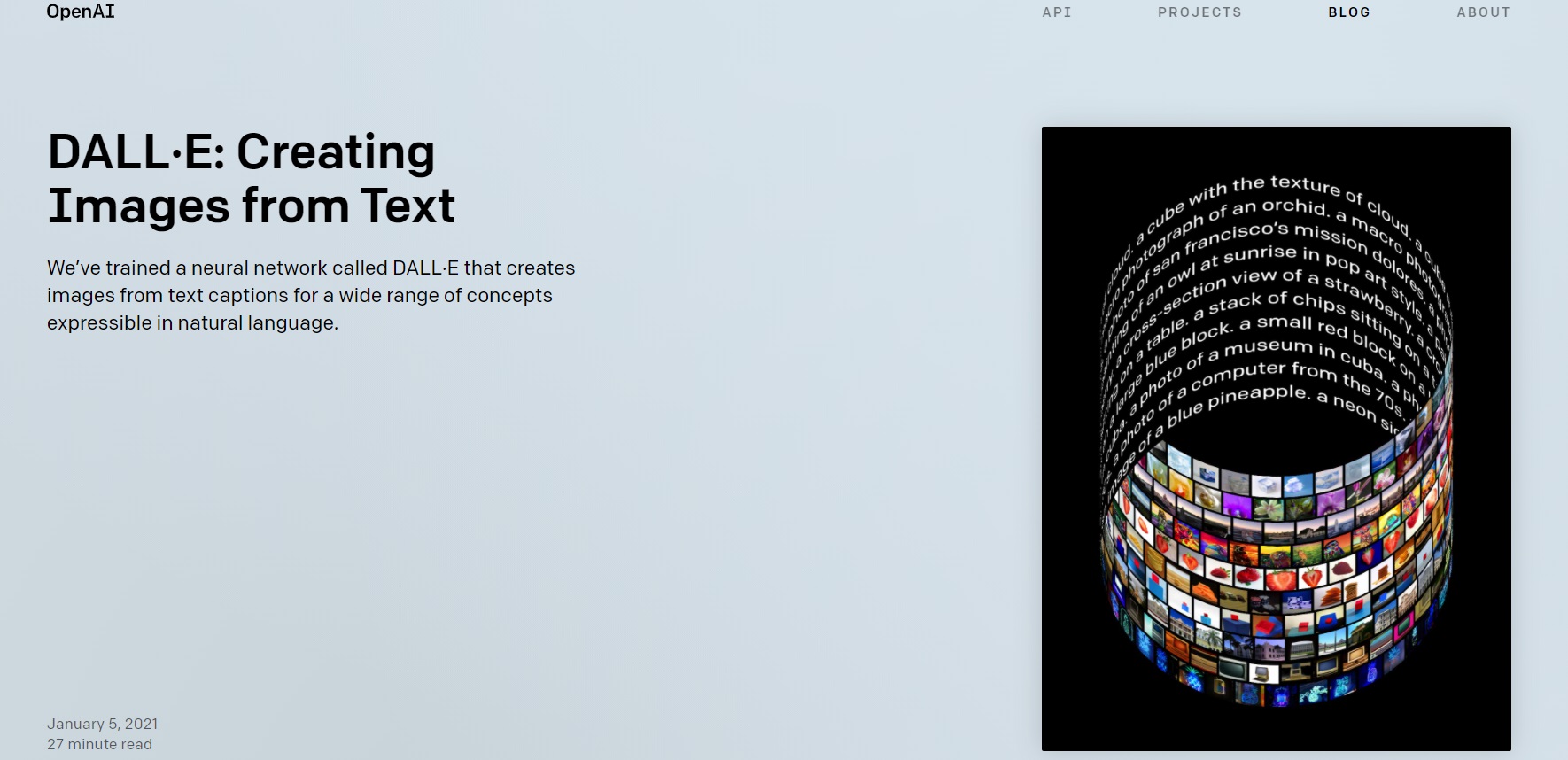

大家在被甲方支配改了一稿又一稿之后,有没有产生过这样的想法,如果有一个系统,我们输入文本就能智能生成设计图,那该有多好啊!其实,未来,可能真的可以实现,因为目前用语言来操纵视觉概念已经可以实现啦!
接下来就要给大家介绍的 DALL·E,就是这样一个神奇的网站,也被称作一个被构建的神经网络,可以根据文本来智能生成各种图像。目前该系统可以根据固定的文本模板,通过替换关键词智能生成各种各样的图片,不论是现实的物体还是概念化的想象都可以生成出来,随我一起来玩玩吧。
值得一看的三个理由:
- 根据文本智能生成图片的系统
- 有趣好玩,可替换关键词实现多样效果
- 接轨未来,智能的设计趋势之一
DALL·E
网站链接:https://openai.com/blog/dall-e/
(搭梯子访问速度会更快)

1. 单个对象:控制属性
文本描述:五边形的绿色时钟(控制形状为五边形,颜色为绿色)

画了横线的地方是可以替换的,大家可以根据自己的喜好去尝试,例如我把形状-五边形换成了三角形,把颜色-绿色替换成了粉色,把对象-闹钟替换成了午餐盒。
文本描述:三角形的粉色午餐盒

2. 多个对象:控制位置和属性
文本描述:一个红色小盒子在一个绿色大盒子的上面。

但是对多个对象时,由于对象各自属性和空间关系的复杂性,相对于单一对象就没有那么精确,例如下图是大绿盒子在小红盒子的左边,可以看出红色框框圈住的部分并不符合这一文本要求,据官方分析发现成功率可能取决于文本的措辞方式,因此这一方面还需要系统内部进行进一步的训练。

例如一个戴着蓝色帽子和红色手套,穿着绿色衬衫和黄色裤子的小企鹅表情符号,我们也会发现有一些错误,有些企鹅穿着黄色和蓝色的衬衫。同样企鹅和颜色可以替换,大家不如自己去探索一番。

3. 可视化透视图
这个特别有意思,可以把自己当成一个摄影机视角,用鸟瞰、特写、鱼眼镜头等等来拍摄出现在森林中或山坡上的美洲狮、穿山甲、鹰等等动物,
文本描述:用特写看一只在森林里的狐狸

4. 实现三维效果
人物的三维效果也在训练中,这里我选择展现的是苏格拉底的侧脸,你也可以选择埃及艳后、美杜莎等等人物。

还能想象和模拟各种镜中反射和光影效果,下图是一只金毛在镜中反射的生成图。

5. 可视化物体的内部结构或外部细节
- 内部的结构
文本描述:汽车的横截面(草莓、人脑、树木、火箭等等)

- 外部的细节
文本描述:蝴蝶翅膀上的细节(蘑菇、树叶、棉花糖等等)

6. 智能推断补充空白
文本描述:一件 T 恤衫上面印着“ACME”
填补的空白:T 恤的颜色和款式,字体

文本描述:一家店面上面写着“PEEKABOO”
填补的空白:字体类型,店面样式和颜色

7. 应用于时装和室内设计
- 时装行业
文本描述:一个穿着黑色毛衣,金色裙子的女模特

- 室内设计
文本描述:一盆芦荟在白色的床边。

8. 结合两个无关物体
文本描述:由香蕉做成的猪(口琴、茄子等;蜗牛、刺猬等)

文本描述:一个模仿牛油果的手扶椅(草莓、孔雀等;咖啡桌、灯等)

9. 复杂的插图
- 动物和物体的拟人化
文本描述:穿着圣诞毛衣的皮卡丘在堆雪人(西装等;兔子、白菜等;看电视、下棋等)

- 不同动物的结合体
文本描述:一个由乌龟做成的长颈鹿(龙、象、鸡、海星等)

- 表情符号的运用
文本描述:一碗拥有可爱表情的拉面(困惑、害怕等;萝卜、榴莲等)

10. 在原图上进行改变
文本描述:上图为一只猫,下图为一只戴了墨镜的猫(戴耳机、戴帽子等)

11. 空间的变化
文本描述:来自中国的食物(各个国家;植物、动物等)

12. 时间的变化
文本描述:相机照片(海报、电脑、杂志等)

看完是不是惊叹于现在技术的智能化程度呢?随着技术的发展,人工智能技术会逐步便利于我们生活的方方面面,不过不必担心人工智能会威胁到我们的安全,因为开发这一神经网络系统的公司 OpenAI 的目的是为了发现并建立人工智能安全的发展道路~如果对这一系统是如何构成感兴趣的朋友,可以去深挖一下官网哦。
















暂无评论内容